Enterprises must look at a Unified Data and Analytics interface
Enterprise Data Architecture, Data Products, Modern Data Stack(MDS), Unified Data and Analytics Interface

Background
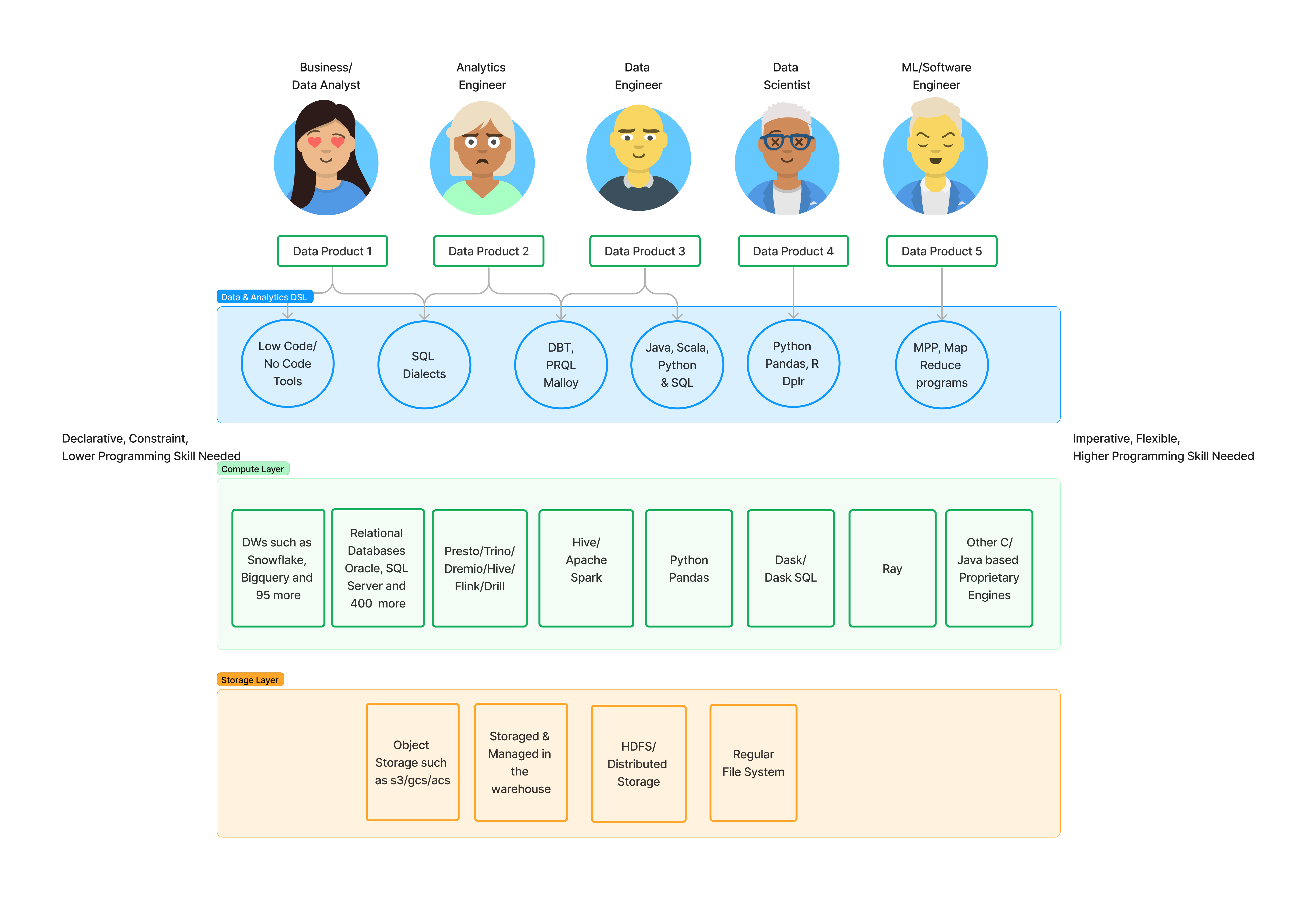
As data became more and more important, a newer set of roles such as data/analytics engineers, data scientists, ML engineers, citizen data analyst have emerged in addition to the existing roles such as data and business analyst.
Further, a new set of use cases have emerged over the past decade with wider enterprise interests. These use cases go beyond the more traditional ad-hoc analytics and traditional business intelligence dashboards/reports.
The emergence of newer data use cases and newer set of data producers in the enterprise coupled with fast pace changes in the technology landscape has created an undesired effect in terms of duplication of data models in many cases, copies of data between various repositories, adoption of multitude of modeling and domain specific languages(DSL)and dialects within those classes of DSLs, as well as data products spread across these DSLs/platforms and third party tools deployed for specific use cases.
As a result of this fast paced evolution, siloed data products in many forms and shapes now reside in multitude of code repositories/databases/warehouses/data lakes further making the overall data architecture further complex.
A unified data and analytics layer could offer a great relief for all future data product investments and help enterprises decouple the data products from the underneath data platform/compute choice.
Following are some of the benefits of choosing a unified data and analytics interface
Make applications and data products independent of the underlying data platform.
Harmonize across various dialects of a given DSL(for ex. various SQL dialects and various dataframe api semantics)
Standardize interfaces restrict tight coupling with various commercial api/sql interfaces.
Take advantage of the available choice of engine without worrying about portability of data products built using unified layer.
Minimize/reduce the cost of migration.
Investment protection in data products and applications.
Expanding use-cases driving newer forms of DSLs
Many use cases have emerged in the past 5-10 years making a case for expanding the list of DSLs for data programming.
These use cases often fall in many of the below categories:
Domain Models: Use cases for building complex domain/entity models to get a 360 degree view of what's happening at a given point in time with a given business entity or operational process. Use cases vary from business to business and industry verticals, But as enterprises grow and become more complex and more dynamic, it often becomes extremely difficult to capture what's really happening with a given business entity. Without having a well defined business data model, it is often not easy to perform ad-hoc analysis from raw data models quickly.
Iterative Exploratory Data Analysis: These are often carried out by data scientists to understand the features and its impact on a specific outcome.
Feature Engineering for Predictive Learning: Involves Data Cleaning, Transformation and Feature Engineering for predictive modeling.
What-if Analysis and Scenario Planning: Helps create different models, scenarios, and Data Tables to calculate a range of probable outcomes. This information allows enterprises to make more informed decisions.
Other Decision Optimization use cases
Domain Specific Language (DSL) Landscape
Various DSLs both commercial and open source have emerged over years. These DSLs can be classified broadly based on the following landscape.
Declarative vs Imperative: Imperative languages help explicitly control the flow of the task. A good example would be SQL vs DataFrames
Level of flexibility and degree of constraints: Data use cases often need a far more extensive set of transformations not yet supported in SQL, necessitate more flexibility on various aspects including mixed datatypes, newer set of operators as well as more control on task execution steps both in defining the task sequence as well as for debugging and troubleshooting in runtime by adding defensive programming checks. Dataframes are one such DSL initiative which enables more control and finds its roots in statistical analysis of data. They essentially allow you to do all the relational algebra that one can do with SQL and more.
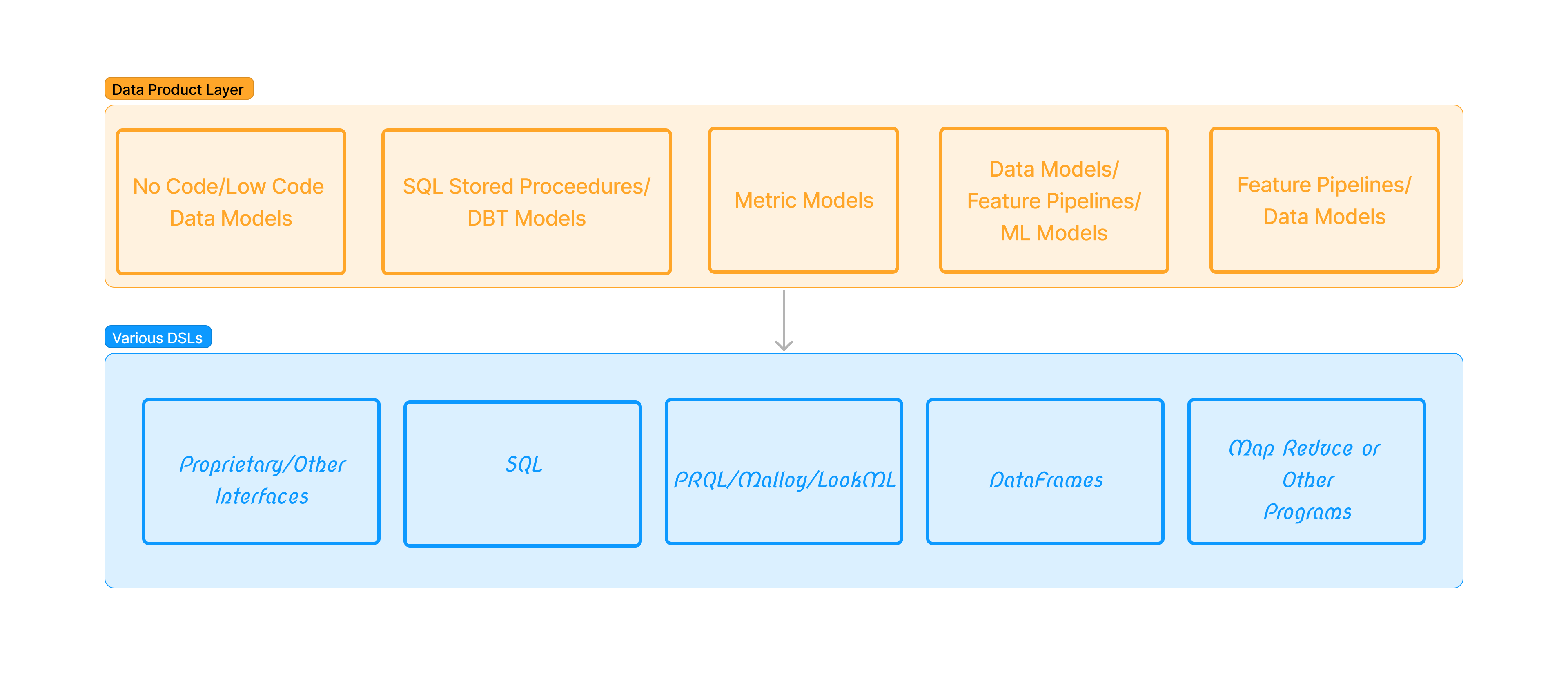
Skill level of Data Producer: No code, Low code, SQL, templatized SQL(ex.DBT), Dataframes and similar relational libraries in various languages such as R, Python, Java, Scala etc.
Use cases and Applications: SQL is a predominant DSL used by data analysts often for ad-hoc query, point questions. On the other end of the spectrum, Data and Analytics Engineer take it to another extreme where they build complex data models such as customer 360, etc. While Dataframes started off supporting the use cases including iterative exploratory data analysis and now being used for complex data pipelines and machine learning applications. There are other DSLs such as malloy, PRQL which form a middle path while following declarative paradigms that address the gap or inefficiencies in SQL constructs.
Classification based on the origin of the specific DSL/Dialect
Database/Data Warehouse
Datalake/Hadoop community
Python/R/Java community.
No-code/low-code origination
Further these classes of DSLs don’t follow common dialect across commercial engines/products, in fact there are often quite a few differences between dialects of the same class of DSLs.
SQLs: Follows a declarative paradigm and is targeted at Data Analyst (typically non software engineers). Unlike the popular perception, It is anything but a single declarative language although many claim the origin to be ANSI SQL. It has many dialects and each differs from the other. Most dialects often differ from standard ANSI SQL Standard by commercial intent and not by accident.
Python based DSLs: These DSLs by and large are part of the imperative class of DSL and need to offer more flexibility to extend, expand the original purpose unlike a declarative language paradigm like SQL. Dataframe being the popular construct here, there are multiple popular choices of libraries such as Pandas, Koalas, Pyspark Dataframes, Snowpark and many more. A few of those choices are tied to the commercial MPP or Map reduce engine that they extend. Like SQL, there’s no single standard and scope of Dataframe API semantics and differs by the library one uses.
R: DSLs in R primarily follow Data Frame semantics. Infact, R essentially can take the credit for the earliest implementation of data frames. A few of the popular options here are Dplr, datatable.
Middleware Tools: DBT, one of the new DSL options promises to help improve how enterprises manage the SQL based declarative procedures by borrowing some of the concepts from software engineering but still keeping the constraint programming environment for skill levels that data/business analyst possess. Other middlewares such as Google’s malloy and PRQL strive to make SQL more simpler (many things are still quite complicated to achieve in SQL) and improve convergence across various dialects.
Other Languages/Tools:
Then there are proprietary interfaces in Java/Scala or Rust or DAX in the old world of Excel. Add to the list of choices the low code/for code/no code tools from Informatica, Alteryx, Talend each use proprietary interfaces to achieve the data modeling.
Some of the BI tools, No/Low code data modeling/transformation tools and commercial products further innovated on DSL which tried to address the gaps in SQL as a DSL for OLAP or Data modeling or other use cases, even when they underneath used SQL for programming the relational databases, they promised to provide simpler user interfaces for a category of use-cases.
Quick Word on SQL Dialects
In the old world of relational databases, the query interface, compute layer and the storage layer were tightly coupled. One didn’t have the choice to reuse the SQL data products used for one relational database and use it in another relational database.
As we moved to the world of big data and cloud warehouse, separation of storage and compute engine became quite a differentiator, since decoupling of compute from storage led to the ability to vertically scale each of them infinitely, and removing the constraints on running multiple simultaneous workloads using virtual warehouses.
However, while storage and compute were decoupled, the sql dialect/logic layer continued to be tightly coupled to the data warehouse one chose. For example, data products written on Snowflake SQL would not be compatible with Big query, without significant effort to migrate data products written in Snowflake to Bigquery. Likewise, data products written in Bigquery to PostgreSQL.
Enterprises today have data products locked up in multiple relational databases and data warehouses and aren’t easy to migrate without costly migration effort.
How could such a unified data and analytics layer emerge?
It’s clear that such a layer would emerge only if the demand side of the equation is compelling. Enterprises find the value proposition and need compelling and demand future data products adopt standardized interfaces. On the supply side, there are currently various open source and potential standardization attempts to look at currently which offer promise, however each has evolution & journey of its own. These efforts can be classified broadly into 3 classes of solutions
Code Abstraction based approach, where a unified user interface replaces individual apis/commercial libraries for build out of the data product. For example, dataframe abstraction → Pandas or Snowpark or Pyspark or Dask or Modin.
Transpilers to convert from one dialect to another. For example, Dataframe to Spark SQL, or PostgreSQL to any other popular SQL dialect such as google sql, snowsql, oracle etc.
Standardization and Serialization of relational algebra used to build out all of these different dialects.
Conclusion
A standards based Unified Data and Interface has the potential to decouple enterprise data products from the underlying data platform and specific dialects, ensure longevity of such investments while simplifying the overall data architecture.